Auckland Suburbs - Part 1
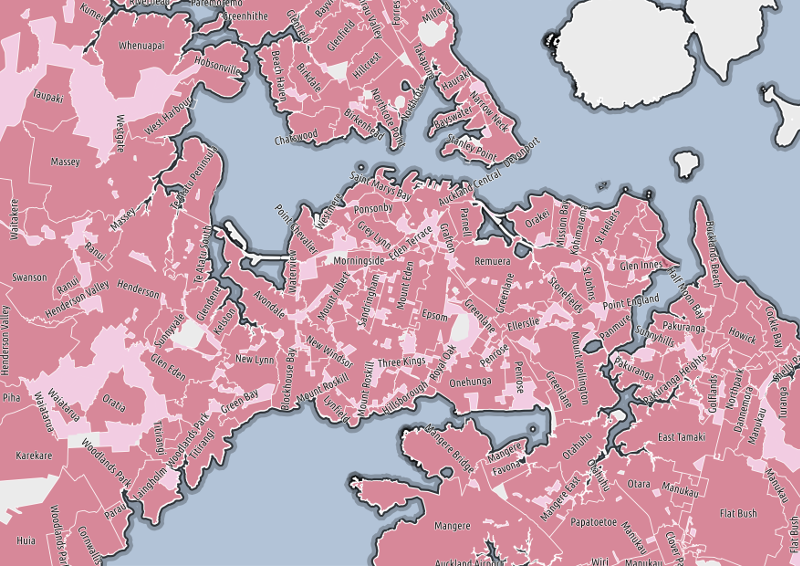
So, suburbs. You're probably looking at this map and wondering "what's the big deal?". It's a terrible map of the suburbs of Auckland. There are lots of holes. Some bits are downright inaccurate. And you'd be right to wonder. Then again, you might be someone who has once tried to acquire an authoritative, free and open dataset of suburbs for Auckland (or, better yet, the whole of New Zealand).
If you're in the latter group, then you're lucky enough to have experienced the strange black hole of rationality that surrounds the NZ Localities dataset held - oddly enough - by the New Zealand Fire Service Commission. And if so, you probably have an idea of why the map above is significant.
I'll write a bit more about the Commission at a later date (the Commission is not be confused with the New Zealand Fire Service, mind. The Commission is the board that oversees the actual Fire Service, it pays to be pedantic when dealing with agencies and the OIA). It's a cautionary tale for all open data advocates.
So here we are: we want to know about suburbs, but we can't use the official data. We'll need to get it elsewhere. Fortunately there is another CC-BY dataset that does have a locality field that looks a lot like a suburb1. This is the New Zealand Electoral Address dataset from LINZ:
This layer provides all allocated addresses as advised to LINZ by Territorial Authorities (TAs). Under the Local Government Act 1974 (section 319) it is the responsibility of the TAs to advise LINZ (the Surveyor General) of all allocated addresses in their district.
How do we go from the point layer to suburb polygons? I first tried calculating Concave Hulls over the locality but the results were.. not great. However the priority for LINZ is to correctly locate addresses within Stats NZ Meshblocks. So we can assign the address locality to the containing meshblock in Postgres, including a count of the times that locality name appears, like so (where I've already imported the Statistics Meshblocks as meshblocks and address points as electoral-addresses:
SELECT
mb.id,
mb.geom,
ad.locality,
count(*) as locality_count
INTO "meshblock-localities"
FROM "meshblocks" as mb
INNER JOIN "electoral-addresses" as ad
ON ST_Intersects(mb.geom, ST_SetSRID(ad.geom, 2193))
WHERE mb.ta2014_nam = 'Auckland'
GROUP BY mb.id, ad.locality
ORDER BY ad.locality, locality_count DESC
This new table meshblock-localities now has duplicate meshblocks for each locality found, so we select distinct meshblocks by picking the most common locality found:
SELECT DISTINCT ON (id) locality, locality_count, geom
INTO "meshblock-localities-distinct"
FROM "meshblock-localities"
ORDER BY id, locality_count DESC;*/
Finally, we still have individual meshblocks, but we really want to join localities together to form single polygons:
SELECT
locality,
ST_UNION(geom) as geom
INTO "meshblock-localities-union"
FROM "meshblock-localities-distinct"
GROUP BY locality;
Now our table meshblock-localities-union has just the
locality name and it's geometry. I've then imported it into
QGIS and performed some additional cleanup:
- Split multi-part geometries. There are a lot of small blocks that are geographically distinct with odd (sometimes hyphenated) names.
- Remove some spurious records, e.g. localities like "Auckland" - probably assigned to addresses that are not obviously in a well known suburb.
The result: a rough starting point to build a proper suburb dataset, from CC-BY licensed data sources.
Datasources
- New Zealand Electoral Address (Land Information New Zealand)
- New Zealand 2014 Clipped Meshblock Boundaries (Statistics NZ)
Footnotes
1. It turns out that the locality field is indeed, slightly indirectly, from the NZFS locality boundaries. More on that in Part 2.